

Left-hand and right-hand version 1 prototypes of Personal Primer (PP) artifact with integrated speech capabilities, e-ink displays and touchless gesture command & control interface.

Anyone can build his own Personal Primer from publicly available off-the-shelf components.
.png)
Homepage of https://fibel.digital

Microsoft's Schlaumaeuse is a well-known DRAA among German pre-schoolers.

Google's Read Along app belong to most well-known DRAAs.
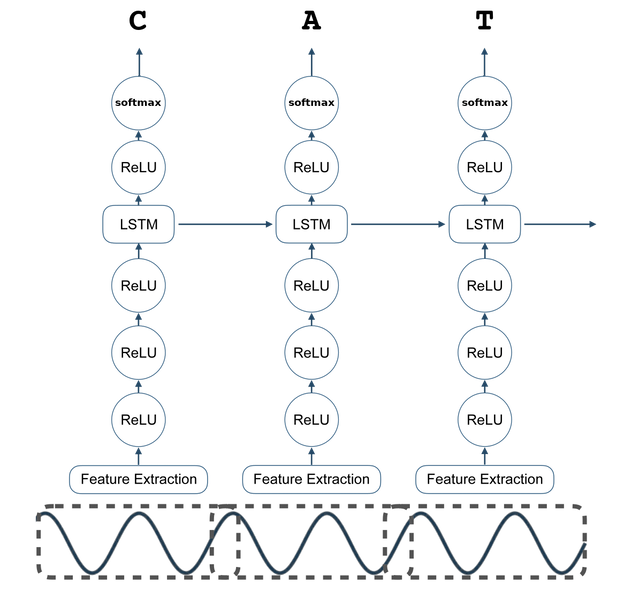
Mozilla's DeepSpeech ASR Architecture

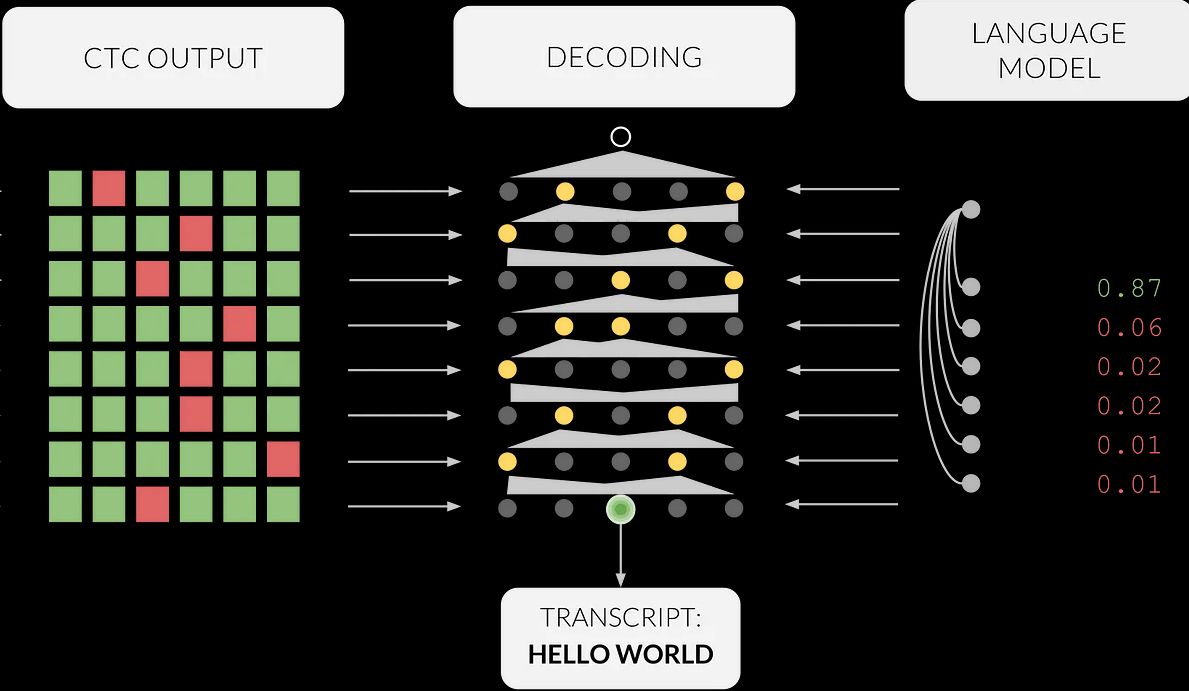
Output of Primer's ASR system combining DeepSpeech acoustic model with language model specific to German-verb recognition exercise.
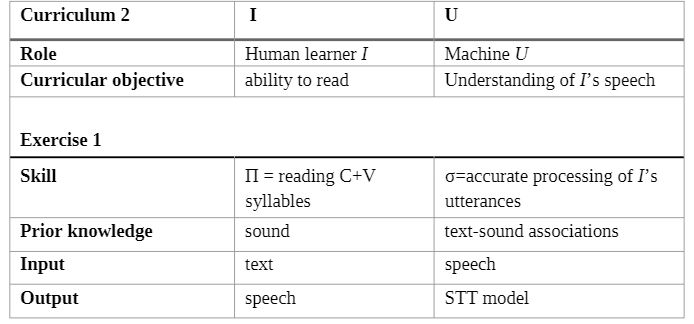
HMPL Curriculum 2 (HMPL C2) introduced in IHIET paper is a sequence of exercises at the outset of which the human individual I acquires the ability to read texts while the artificial utterance-processing tutor U acquires the ability to accurately process I's speech.
.png)
Screenshot from web-based interface for mutual human-machine learning phase of HMPL-C2-E1 preliminary study.
|
Day 1 |
Day 3 |
Day 5 |
DeepSpeech_DE |
0.96 |
0.84 |
0.64 |
KIds0 |
0.74 |
0.72 |
0.68 |
KIdsL1-1 |
0.69 |
0.78 |
0.44 |
KIdsL1-3 |
0.69 |
0.8 |
0.52 |
KIdsL1-5 |
0.69 |
0.74 |
0.48 |